Training Neural Networks¶
Backpropagation is the most common training algorithm for neural networks. It makes gradient descent feasible for multi-layer neural networks.
Best Practices¶
This section explains backpropagation's failure cases and the most common way to regularize a neural network.
Failure Cases¶
There are a number of common ways for backpropagation to go wrong.
Vanishing Gradients¶
The gradients for the lower layers (closer to the input) can become very small. In deep networks, computing these gradients can involve taking the product of many small terms.
When the gradients vanish toward 0 for the lower layers, these layers train very slowly, or not at all.
The ReLU activation function can help prevent vanishing gradients.
Exploding Gradients¶
If the weights in a network are very large, then the gradients for the lower layers involve products of many large terms. In this case you can have exploding gradients: gradients that get too large to converge.
Batch normalization can help prevent exploding gradients, as can lowering the learning rate.
Dead ReLU Units¶
Once the weighted sum for a ReLU unit falls below 0, the ReLU unit can get stuck. It outputs 0 activation, contributing nothing to the network's output, and gradients can no longer flow through it during backpropagation. With a source of gradients cut off, the input to the ReLU may not ever change enough to bring the weighted sum back above 0.
Lowering the learning rate can help keep ReLU units from dying.
Dropout Regularization¶
Yet another form of regularization, called Dropout, is useful for neural networks. It works by randomly "dropping out" unit activations in a network for a single gradient step. The more you drop out, the stronger the regularization:
- 0.0 = No dropout regularization.
- 1.0 = Drop out everything. The model learns nothing.
- Values between 0.0 and 1.0 = More useful.
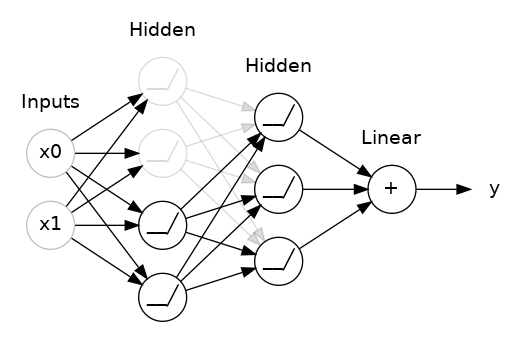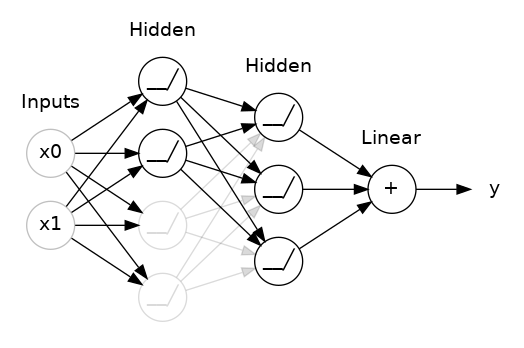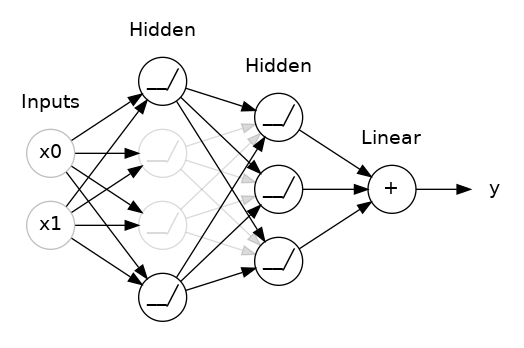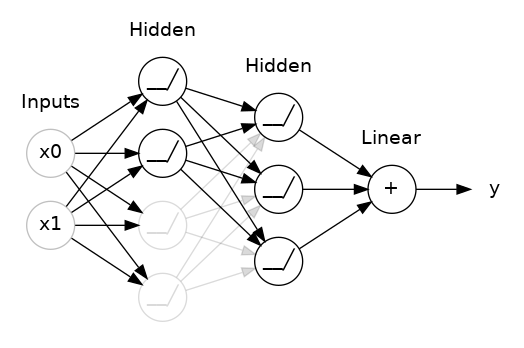 Here, 50% dropout has been added between the two hidden layers.
Here, 50% dropout has been added between the two hidden layers.
Batch Normalization (batchnorm)¶
With neural networks, it's generally a good idea to put all of your data on a common scale. The reason is that SGD will shift the network weights in proportion to how large an activation the data produces. Features that tend to produce activations of very different sizes can make for unstable training behavior.
Now, if it's good to normalize the data before it goes into the network, maybe also normalizing inside the network would be better! In fact, we have a special kind of layer that can do this, the batch normalization layer. A batch normalization layer looks at each batch as it comes in, first normalizing the batch with its own mean and standard deviation, and then also putting the data on a new scale with two trainable rescaling parameters. Batchnorm, in effect, performs a kind of coordinated rescaling of its inputs.
Most often, batchnorm is added as an aid to the optimization process (though it can sometimes also help prediction performance). Models with batchnorm tend to need fewer epochs to complete training. Moreover, batchnorm can also fix various problems that can cause the training to get "stuck". Consider adding batch normalization to your models, especially if you're having trouble during training.